
Tags
The combination of my major restructuring of my applications, my experiments with synonyms (still incomplete), and lately the pressing deadline of getting taxes done (three sets, not just mine) has severely eaten into my drills (plus a bit of boredom as well). That provides, indirectly, a bit of experiment by undermining the short-term memory I accumulate with high rates of drills so this pause is a chance for my long-term stats (accuracy per word on drills) to get closer to longer-term knowledge. The history, which is impossible to simulate (or even really test the code) is essential to this application so my lack of activity is actually helpful. So here’s the story, graphically:

The blue markers and line are my actual daily drills (on the full vocabulary, now with 13,273 drills, whew a lot, about 33 hours spent on that over 134 days, or averaging about 15 minutes/day). All those zero starting around day 115 has dragged down my 7-day moving average (the gold markers and line) to the lowest since I started all these drills. Now I have done a few others (about 2000) which I’ll eventually merge into this set but the other drills are on different word sets and will distort things a bit.
Looking at the data a different way:

The flat part of the curve is the recent “pause” with only tiny growth (compared to previous high rate of drills (in essence, this is the integral of the previous graph). So I’ve fallen below my long-term trendline (the dotted regression line) and need to catch up a bit.
And looking at this a different way:
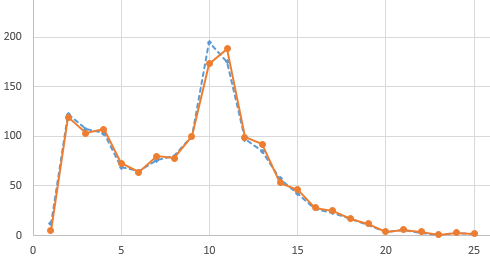
This is the distribution of #drills (horizontal axis) and counts (vertical axis). Since my biased picker should tend to drill more on the less drilled words the gold line (today, after 150 drills) should be lower than the blue line (before today’s drills) on the left side and higher on the right side. But 150 drills is just a bit over 1% of the total number of drills so one day makes little difference. BTW: the bulge in the lower #drills was my addition to this drill file of a few hundred newly setup words just a while back (about a month) so these recent additions still haven’t blended into the long-term pattern. I also found a anomaly in the code (the biased picker) exactly at 10 previous picks and so I’ve fixed that and the large peak at 10 is slowly coming down. Which, btw, is the point of some of these graphs, the only way to look at this huge amount of data and determine the effects of code changes and/or vocabulary content changes, so again a way I can validate what my application is doing (hard to tell just from doing drills which now nearly 2000 words, or, IOW, only doing about 1/10th of them on any given day, hard to see patterns).
So the work goes on.
p.s. While drills may be down meanwhile I have accumulated 935 synonyms in my collection (some of this count is derivatives or inflections) so that’s a significant portion of my total vocabulary (I’m doing synonyms in a separate file format and different process, not sure, yet, how I’ll add these to my vocabulary or exactly what I’ll use them for). So work continues, just in different places. Meanwhile I’ve been very tempting to attempt to recover (what I can) of my Spanish food terms (some of the data I got was clean) but that’s yet another distraction from all sorts of other unfinished work.
